
About Me
I am a Researcher at the School of Education at Tsinghua University. I got my Ph.D degree at the Knowledge Engineering Group (KEG), Department of Computer Science and Technology, Tsinghua University, supervised by Prof. Juanzi Li and Prof. Jie Tang. My research interests focus on Knowledge-driven AI in Education, especially Educational Large Models and Agents. I am leading the THU-MAIC Team and continuously looking for self-motivated, high-caliber collaborators, research assistants, and candidate master’s students. For more details, you can check my Chinese CV or English CV.
Some of our publicly available resources for AI-Edu can be found here:
What’s New ?
- Our OpenMAIC achieved 11k Github Stars in five days!
- We have two papers accepted by ACL 2024, Congrats to Shangqing and Xiaokang!
Invited Talk & Award
- Our Work on Massive Open Online Course won The Prize of First Class for the Wu Wenjun Science and Technology Award (吴文俊人工智能科技进步一等奖), by the Chinese Association for Artificial Intelligence, in 2026.
- MAIC is awarded as Outstanding Educational Case Studies on AI Safety and AI for Good by the Ministry of Education, China.
- Our Paper of Open IE won EMNLP Outstanding Paper.
- VisKop won ACL2023 Best Demo Paper Award.
- MOOCCubeX won CIKM2021 Best Resource Paper Nomination.
- The Knowledgeable Intelligence in MOOCs. (AI Time 2020) Sildes
Selected Publications
2024
 | AI as Learning Partners: Students' Interactions and Perceptions in a Simulated Classroom with Multiple LLM-Powered Agents ICLS 2025 Zhanxin Hao, Fei Qin, Jianxiao Jiang, Jie Cao, Jifan Yu, Zhiyuan Liu, Yu Zhang [PDF] This study explores how students interact with and perceive multiple AI agents in a simulated classroom environment. Findings reveal that students actively engage in both cognitive and regulatory activities, holding generally positive perceptions of AI agents' cognitive support and personalization capabilities. However, limitations in emotional resonance were identified, highlighting the potential of multi-agent systems to enrich educational experiences while underscoring the need for improved emotional engagement design. |
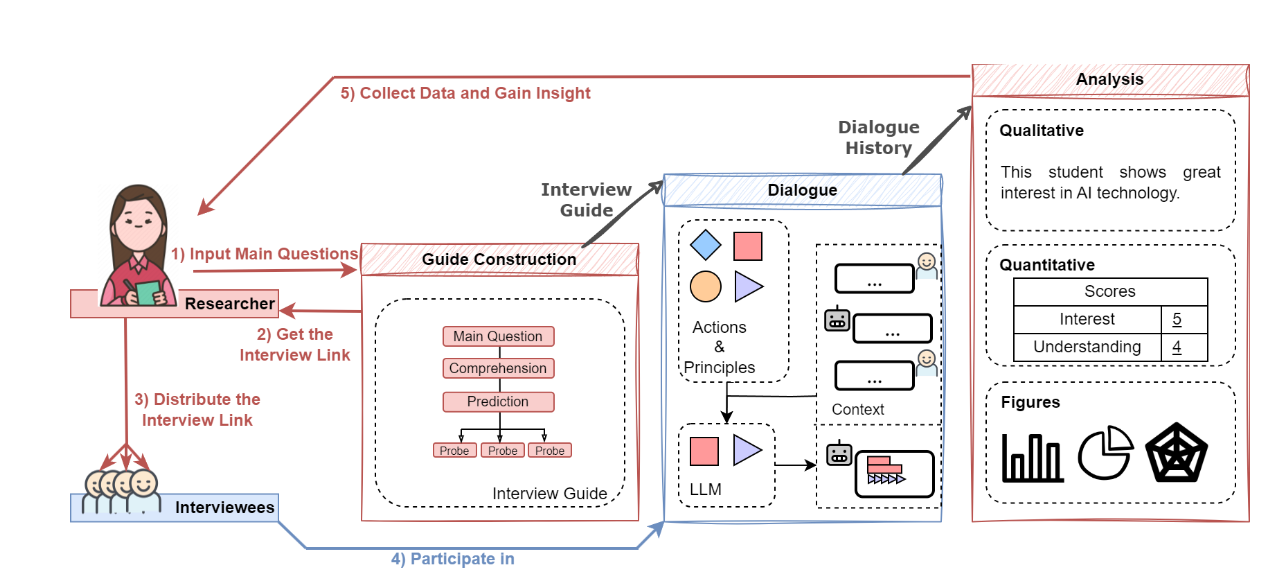 | LM-Interview: An Easy-to-use Smart Interviewer System via Knowledge-guided Language Model Exploitation EMNLP 2024 Demo Hanming Li, Jifan Yu, Ruimiao Li, Zhanxin Hao, Xuan Yan, Jiaxin Yuan, Bin Xu, Juanzi Li, Zhiyuan Liu [PDF] We present LM-Interview, a knowledge-guided language model system that automates the full pipeline of semi-structured interviews, including interview guide construction, intelligent dialogue execution, and multimodal data analysis. By adopting a state-action-reward paradigm for fine-grained control of interview flow, the system supports both qualitative and quantitative analysis dimensions. Experiments in real-world scenarios demonstrate that LM-Interview achieves performance comparable to experienced human interviewers, offering an efficient and scalable solution for qualitative research data collection. |
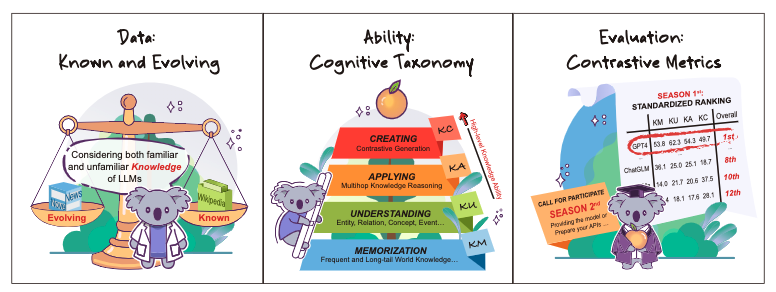 | KoLA: Carefully Benchmarking World Knowledge of Large Language Models ICLR 2024 Jifan Yu*, Xiaozhi Wang*, Shangqing Tu*, Shulin Cao, Daniel Zhang-Li, Xin Lv, Hao Peng, Zijun Yao, Xiaohan Zhang, Hanming Li, Chunyang Li, Zheyuan Zhang, Yushi Bai, Yantao Liu, Amy Xin, Nianyi Lin, Kaifeng Yun, Linlu Gong, Jianhui Chen, Zhili Wu, Yunjia Qi, Weikai Li, Yong Guan, Kaisheng Zeng, Ji Qi, Hailong Jin, Jinxi Liu, Yu Gu, Yuan Yao, Ning Ding, Lei Hou, Zhiyuan Liu, Bin Xu, Jie Tang, Juanzi Li [Platform] [PDF] [Code] We construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) Ability Modeling (2) Evolving Data, (3) Standardized Evaluation. We evaluate 21 open-source and commercial LLMs and obtain some intriguing findings. |
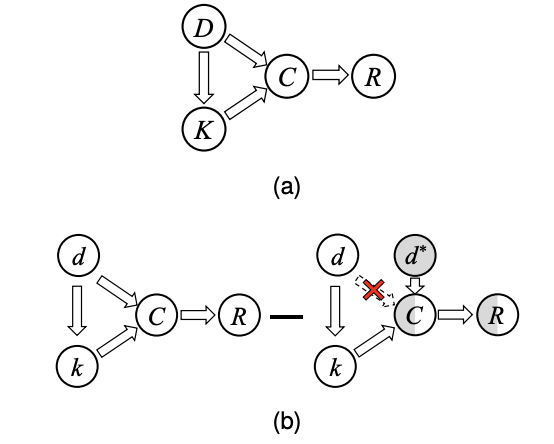 | A Cause-Effect Look at Alleviating Hallucination of Knowledge-grounded Dialogue Generation COLING 2024 Jifan Yu, Xiaohan Zhang, Yifan Xu, Xuanyu Lei, Zijun Yao, Jing Zhang, Lei Hou, Juanzi Li [PDF] In this paper, we analyze the causal story behind this problem with counterfactual reasoning methods. Based on the causal effect analysis, we propose a possible solution for alleviating the hallucination in KGD by exploiting the dialogue-knowledge interaction. |
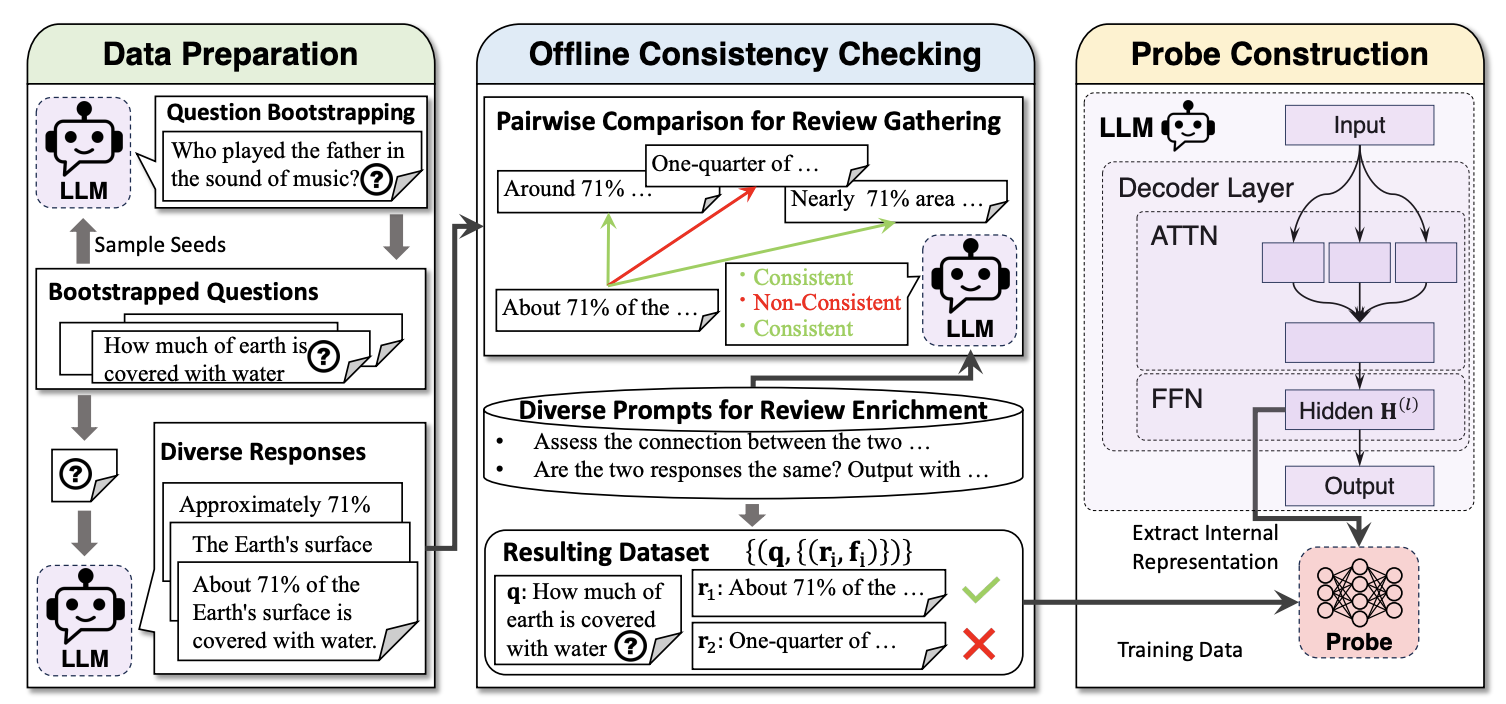 | Transferable and Efficient Non-Factual Content Detection via Probe Training with Offline Consistency Checking ACL 2024 Xiaokang Zhang, Zijun Yao, Jing Zhang, Kaifeng Yun, Jifan Yu, Juanzi Li, Jie Tang [PDF] This paper proposes PINOSE, which trains a probing model on offline self-consistency checking results, thereby circumventing the need for human-annotated data and achieving transferability across diverse data distributions. |
2023
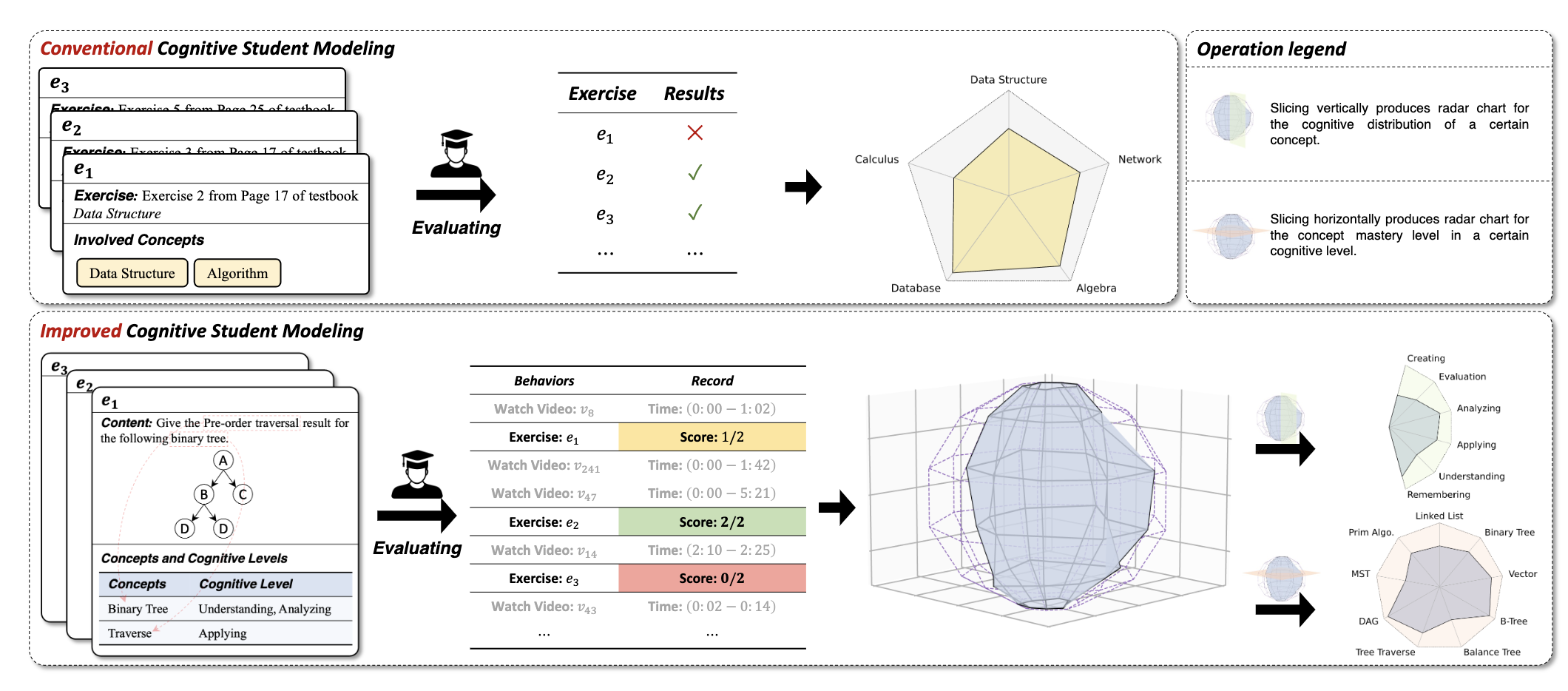 | MoocRadar: A Fine-grained and Multi-aspect Knowledge Repository for Improving Cognitive Student Modeling in MOOCs SIGIR 2023 Jifan Yu, Mengying Lu, Qingyang Zhong, Zijun Yao, Shangqing Tu, Zhengshan Liao, Xiaoya Li, Manli Li, Lei Hou, Hai-Tao Zheng, Juanzi Li, Jie Tang [PDF] [Repository] In this paper, we present MoocRadar, a fine-grained, multi-aspect knowledge repository consisting of 2,513 exercise questions, 5,600 knowledge concepts, and over 12 million behavioral records. Specifically, we propose a framework to guarantee a high-quality and comprehensive annotation of fine-grained concepts and cognitive labels. |
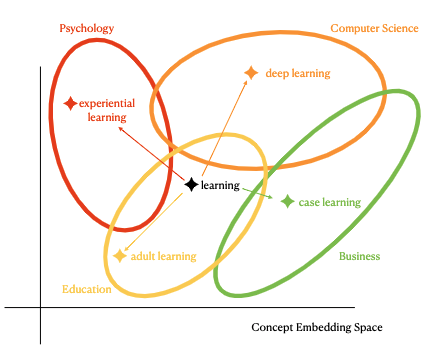 | Distantly Supervised Course Concept Extraction in MOOCs with Academic Discipline ACL 2023 Mengying Lu, Yuquan Wang, Jifan Yu (Corresponding Author), Yexing Du, Lei Hou, Juanzi Li [Dataset & Code] We present a novel three-stage framework DS-MOCE, which leverages the power of pre-trained language models explicitly and implicitly and employs discipline-embedding models with a self-train strategy based on label generation refinement across different domains. |
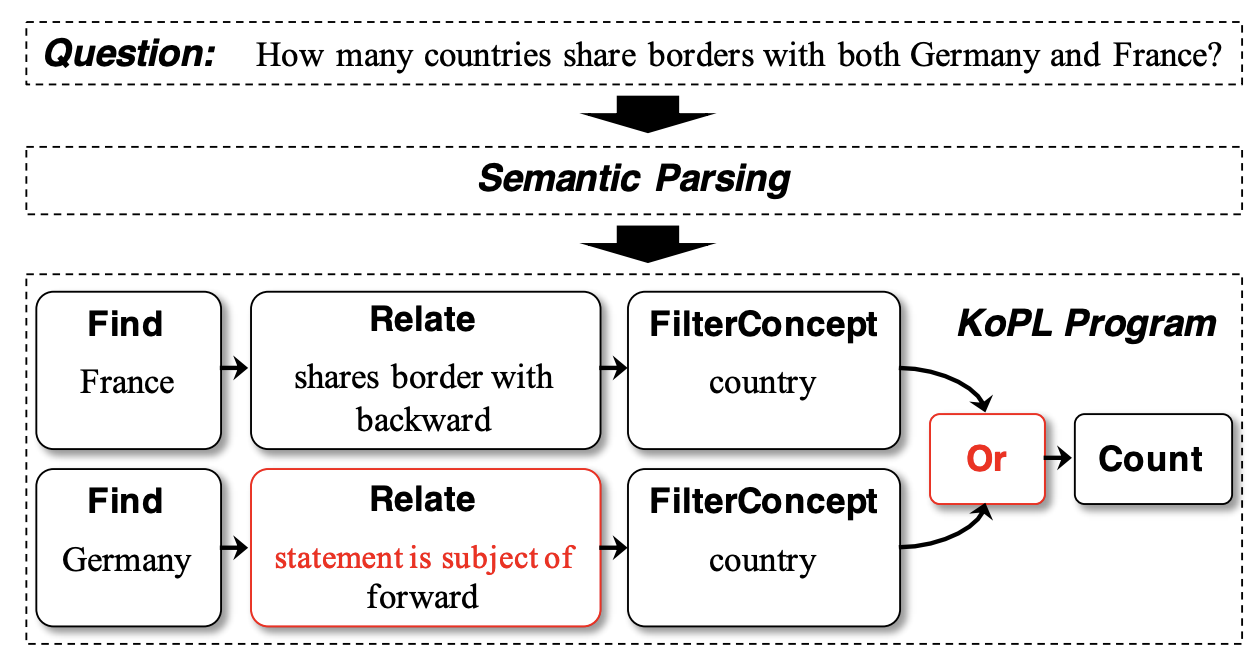 | VisKoP: Visual Knowledge oriented Programming for Interactive Knowledge Base Question Answering (Best Demo Paper Award) ACL 2023 Demo Zijun Yao, Yuanyong Chen, Xin Lv, Shulin Cao, Amy Xin, Jifan Yu, Hailong Jin, Jianjun Xu, Peng Zhang, Lei Hou, Juanzi Li [Paper] [Demo] We present Visual Knowledge oriented Programming platform (VisKoP), a knowledge base question answering (KBQA) system that integrates human into the loop to edit and debug the knowledge base (KB) queries. |
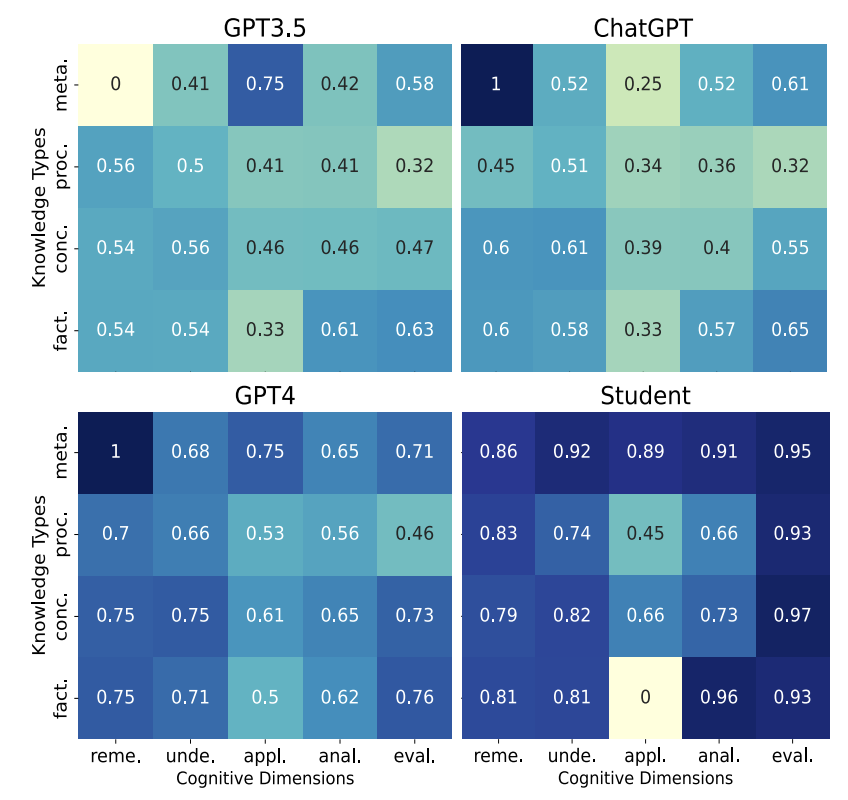 | Exploring the Cognitive Knowledge Structure of Large Language Models: An Educational Diagnostic Assessment Approach EMNLP 2023 Zheyuan Zhang*, Jifan Yu*, Juanzi Li, Lei Hou [Paper] In this paper, based on educational diagnostic assessment method, we conduct an evaluation using MoocRadar, a meticulously annotated human test dataset based on Bloom Taxonomy. |
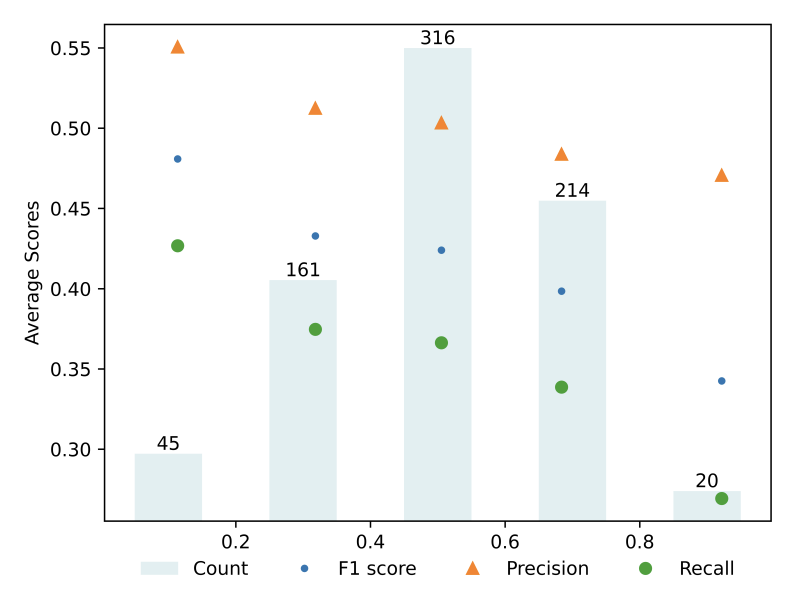 | Mastering the Task of Open Information Extraction with Large Language Models and Consistent Reasoning Environment (Outstanding Paper) EMNLP 2023 Ji Qi, Kaixuan Ji, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Lei Hou, Juanzi Li, Bin Xu [Paper] As the large language models (LLMs) have exhibited remarkable in-context learning capabilities, a question arises as to whether the task of OIE can be effectively tackled with this paradigm? In this paper, we explore solving the OIE problem by constructing an appropriate reasoning environment for LLMs. |
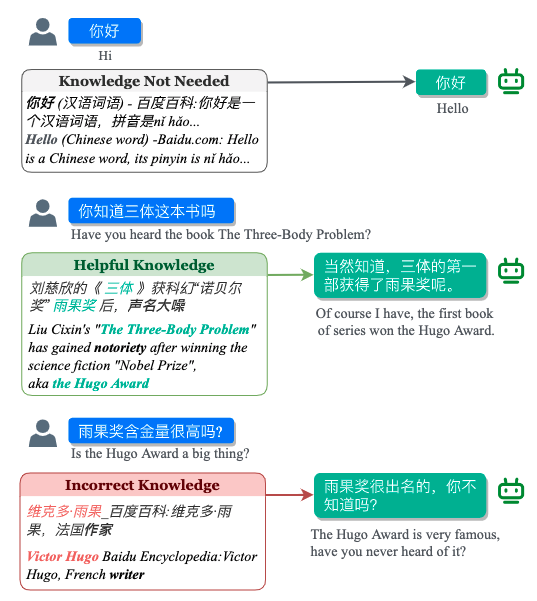 | GLM-Dialog: Noise-tolerant Pre-training for Knowledge-grounded Dialogue Generation KDD 2023 Jing Zhang*, Xiaokang Zhang*, Daniel Zhang-Li*, Jifan Yu*, Zijun Yao, Zeyao Ma, Yiqi Xu, Haohua Wang, Xiaohan Zhang, Nianyi Lin, Sunrui Lu, Juanzi Li, Jie Tang [Dataset & Code] [PDF] We present GLM-Dialog, a large-scale language model (LLM) with 10B parameters capable of knowledge-grounded conversation in Chinese using a search engine to access the Internet knowledge. GLM-Dialog offers a series of applicable techniques for exploiting various external knowledge including both helpful and noisy knowledge, enabling the creation of robust knowledge-grounded dialogue LLMs with limited proper datasets. |
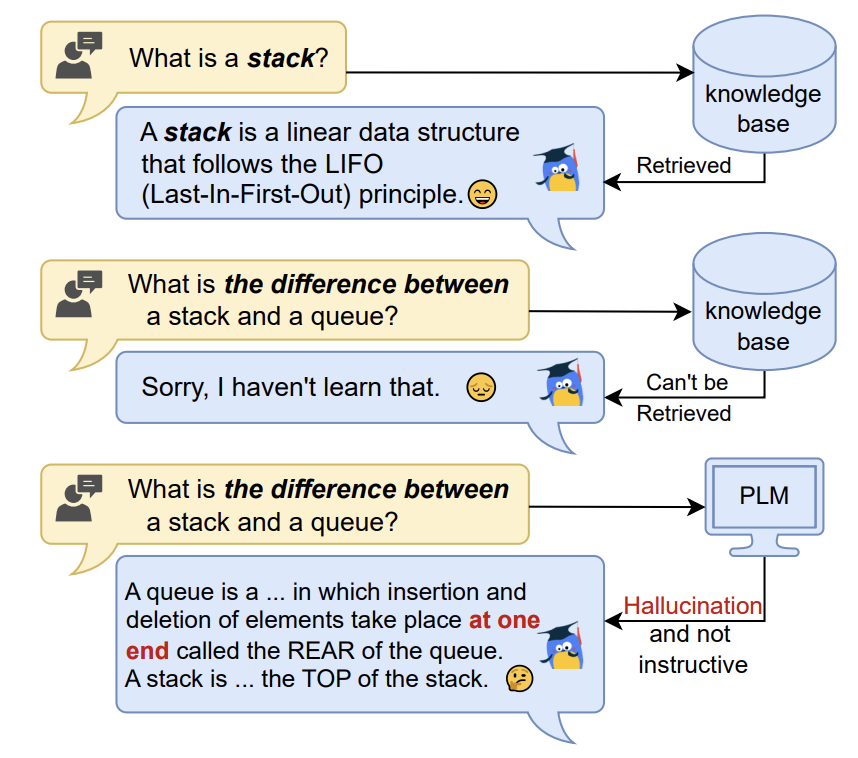 | LittleMu: Deploying an Online Virtual Teaching Assistant via Heterogeneous Sources Integration and Chain of Teach Prompts CIKM 2023 Shangqing Tu, Zheyuan Zhang, Jifan Yu, Chunyang Li, Siyu Zhang, Zijun Yao, Lei Hou, Juanzi Li [PDF] In this paper, we present a virtual MOOC teaching assistant, LittleMu with minimum labeled training data, to provide question answering and chit-chat services. |
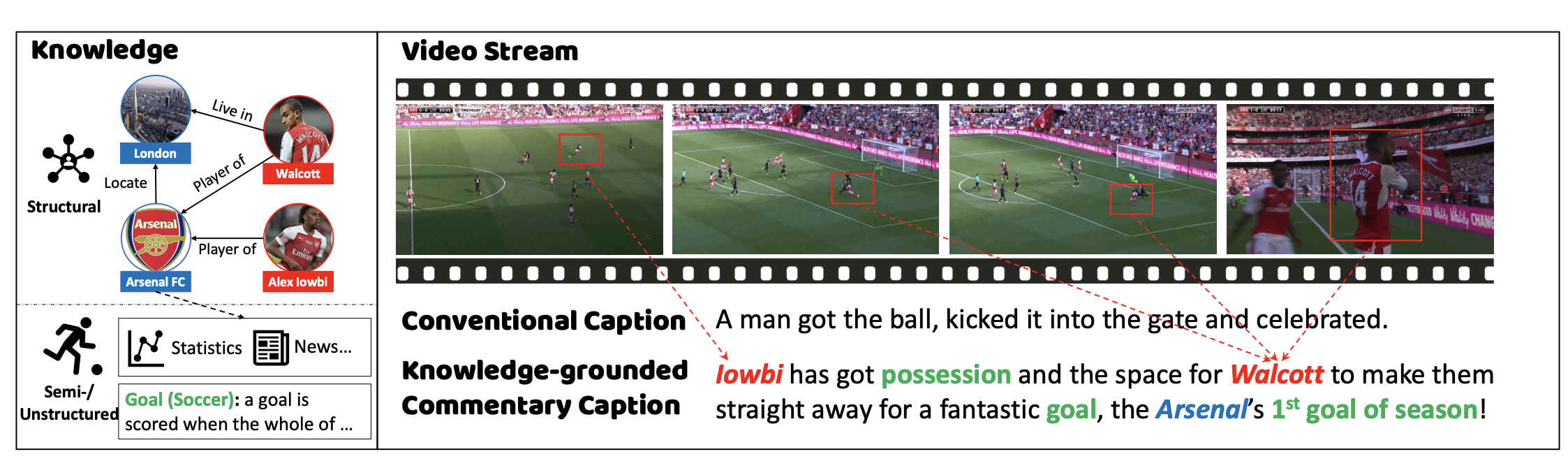 | GOAL: A Challenging Knowledge-grounded Video Captioning Benchmark for Real-time Soccer Commentary Generation CIKM 2023 Ji Qi*, Jifan Yu*, Teng Tu, Kunyu Gao, Yifan Xu, Xinyu Guan, Xiaozhi Wang, Bin Xu, Lei Hou, Juanzi Li, Jie Tang [Paper] [Repository] In this paper, we present GOAL, a benchmark of over 8.9k soccer video clips, 22k sentences, and 42k knowledge triples for proposing a challenging new task setting as Knowledge-grounded Video Captioning (KGVC). |
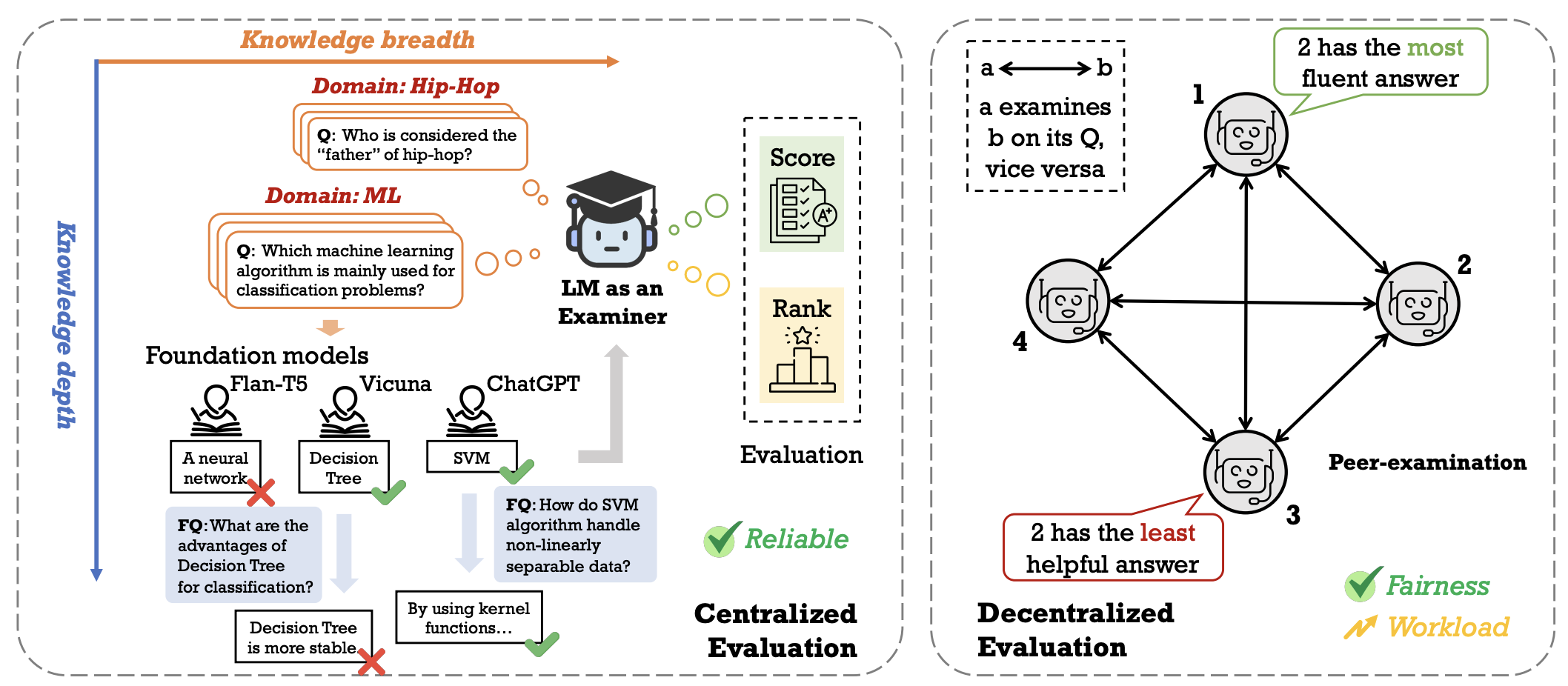 | Benchmarking Foundation Models with Language-Model-as-an-Examiner NeuraIPS 2023 Benchmarking Track Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, Lei Hou [PDF] [Repository] (1) We instruct the LM examiner to generate questions across a multitude of domains to probe for a broad acquisition, and raise follow-up questions to engage in a more in-depth assessment. (2) Upon evaluation, the examiner combines both scoring and ranking measurements, providing a reliable result as it aligns closely with human annotations. (3) We additionally propose a decentralized Peer-examination method to address the biases in a single examiner. |
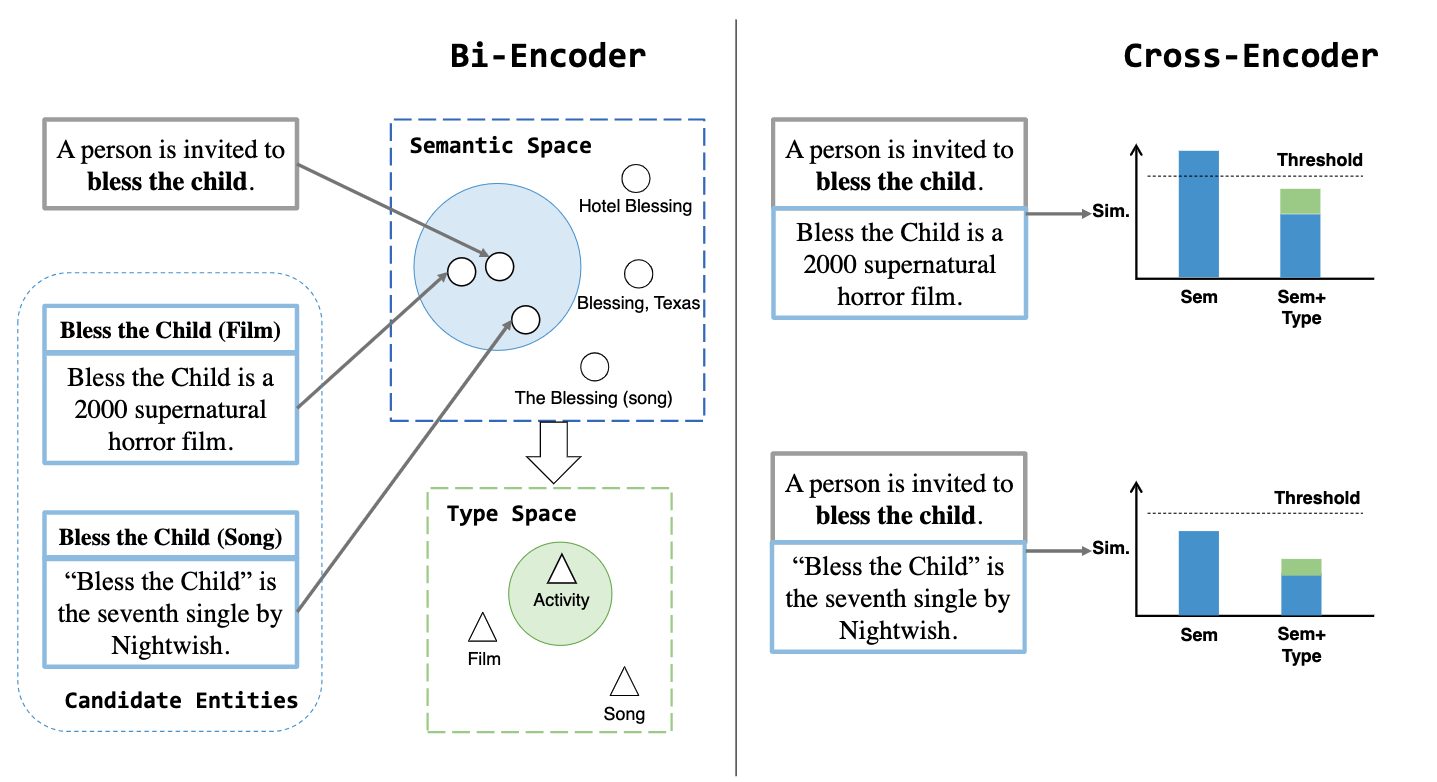 | Learn to Not Link: Exploring NIL Prediction in Entity Linking Findings of ACL 2023 Fangwei Zhu, Jifan Yu*, Hailong Jin, Juanzi Li, Lei Hou, Zhifang Sui [Dataset & Code] [PDF] We propose an entity linking dataset NEL focuses on the NIL prediction problem. NEL takes entities that share an alias with other entities as seeds, collects relevant mention context in the Wikipedia corpus, and ensures the presence of mentions linking to NIL by human annotation and entity masking. |
2022
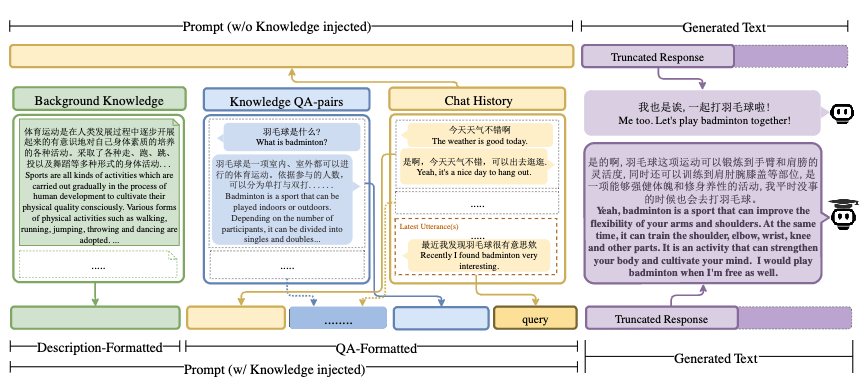 | XDAI: A Tuning‑free Framework for Exploiting the Pre‑trained Language Models in Knowledge Grounded Dialogue Generation KDD 2022 Jifan Yu, Xiaohan Zhang, Yifan Xu, Xuanyu Lei, Xinyu Guan, Jing Zhang, Lei Hou, Juanzi Li, Jie Tang [Code] We propose XDAI, a knowledge-grounded dialogue system that is equipped with the prompt-aware tuning-free PLM exploitation and supported by the ready-to-use open-domain external knowledge resources plus the easy-to-change domain-specific mechanism. |
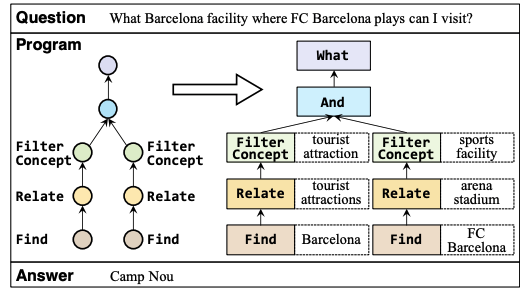 | Program Transfer for Answering Complex Questions over Knowledge Bases ACL 2022 Shulin Cao, Jiaxin Shi, Zijun Yao, Xin Lv, Jifan Yu, Lei Hou, Juanzi Li, Zhiyuan Liu, Jinghui Xiao [PDF] [Code] In this paper, we propose the approach of program transfer, which aims to leverage the valuable program annotations on the rich-resourced KBs as external supervision signals to aid program induction for the low-resourced KBs that lack program annotations. |
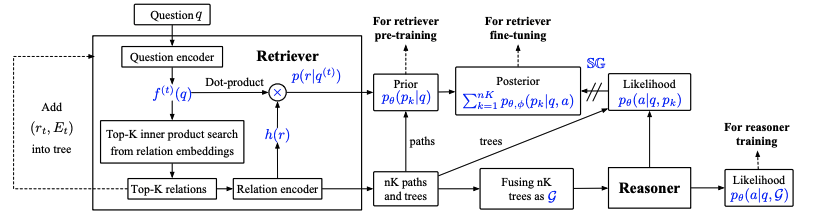 | Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering ACL 2022 Jing Zhang, Xiaokang Zhang, Jifan Yu, Jian Tang, Jie Tang, Cuiping Li, Hong Chen [PDF] [Code] This paper proposes a trainable subgraph retriever (SR) decoupled from the subsequent reasoning process, which enables a plug-and-play framework to enhance any subgraph-oriented KBQA model. |
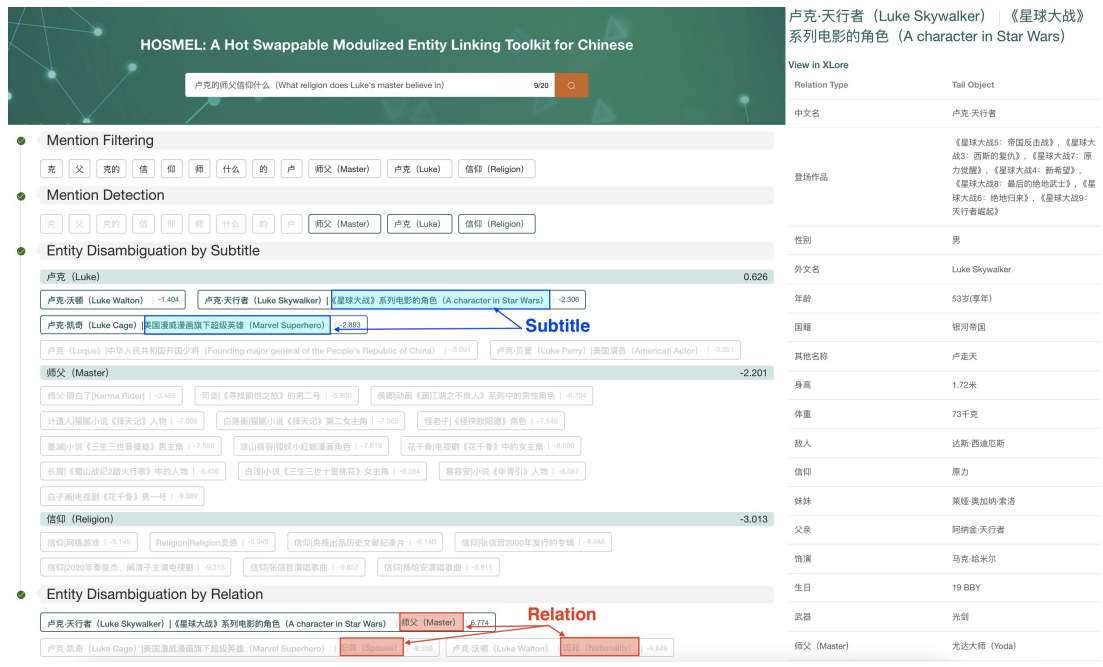 | HOSMEL: A Hot-Swappable Modularized Entity Linking Toolkit for Chinese ACL 2022 Daniel Zhang-Li, Jing Zhang, Jifan Yu, Xiaokang Zhang, Peng Zhang, Jie Tang, Juanzi Li [PDF] [Code] We investigate the usage of entity linking (EL) in downstream tasks and present the first modularized EL toolkit for easy task adaptation. Different from the existing EL methods that deal with all the features simultaneously, we modularize the whole model into separate parts with each feature. |
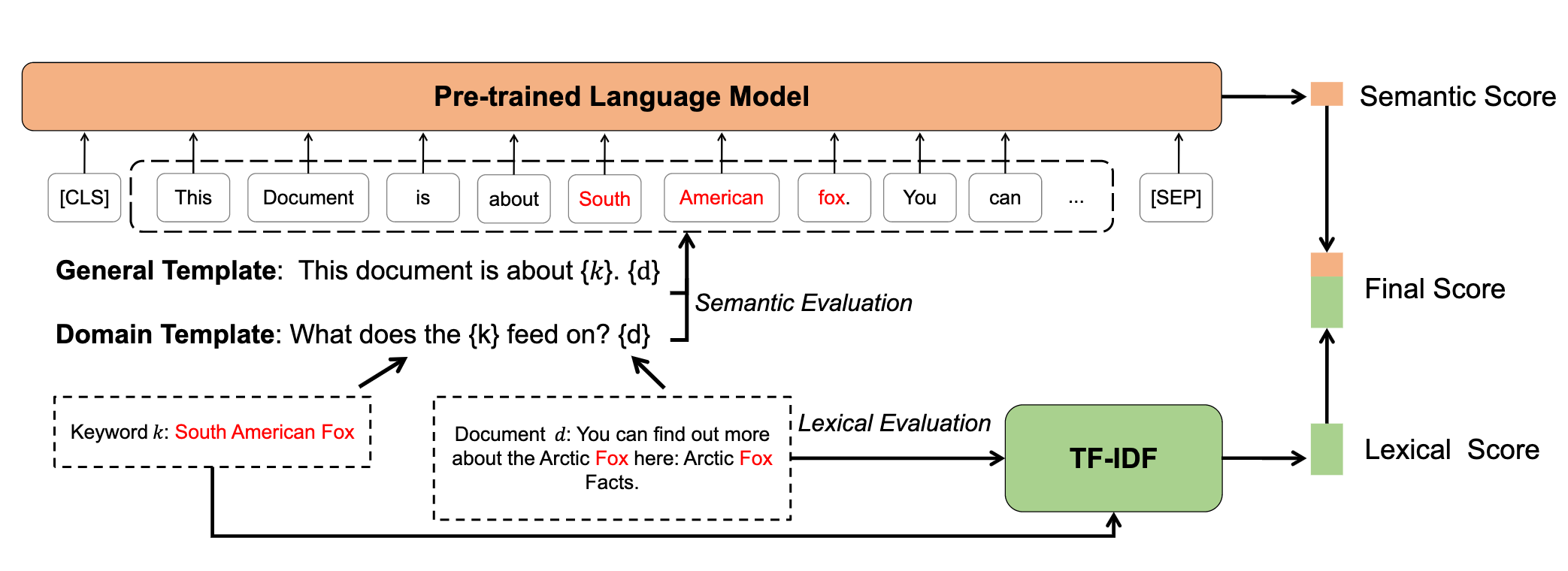 | UPER: Boosting Multi-Document Summarization with an Unsupervised Prompt-based Extractor COLING 2022 Shangqing Tu, Jifan Yu, Fangwei Zhu, Juanzi Li, Lei Hou and Jian-Yun Nie [code] To extract documents effectively, we construct prompting templates that invoke the underlying knowledge in Pre-trained Language Model (PLM) to calculate the document and keyword’s perplexity, which can assess the document’s semantic salience. Our unsupervised approach can be applied as a plug-in to boost other metrics for evaluating a document’s salience, thus improving the subsequent abstract generation. |
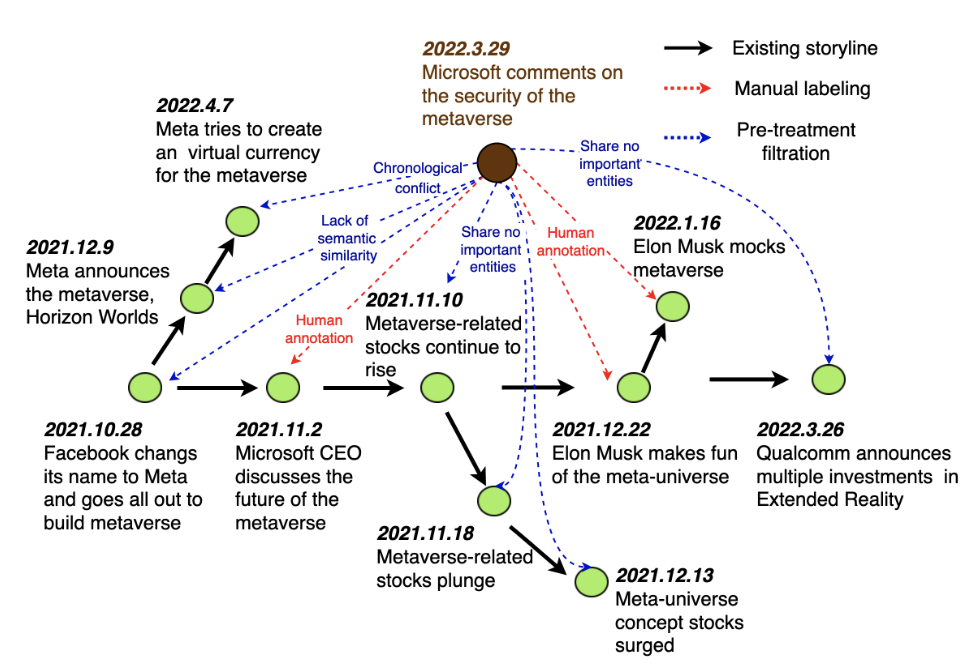 | CStory: A Chinese Large-scale News Storyline Dataset CIKM 2022 Kaijie Shi, Xiaozhi Wang, Jifan Yu, Lei Hou, Juanzi Li, Jingtong Wu, Dingyu Yong, Jinghui Xiao, Qun Liu [code] In this paper, we construct CStory, a large-scale Chinese news storyline dataset, which contains 11, 978 news articles, 112, 549 manually labeled storyline relation pairs, and 49, 832 evidence sentences for annotation judgment. We conduct extensive experiments on CStory using various algorithms and find that constructing news storylines is challenging even for pre-trained language models. |
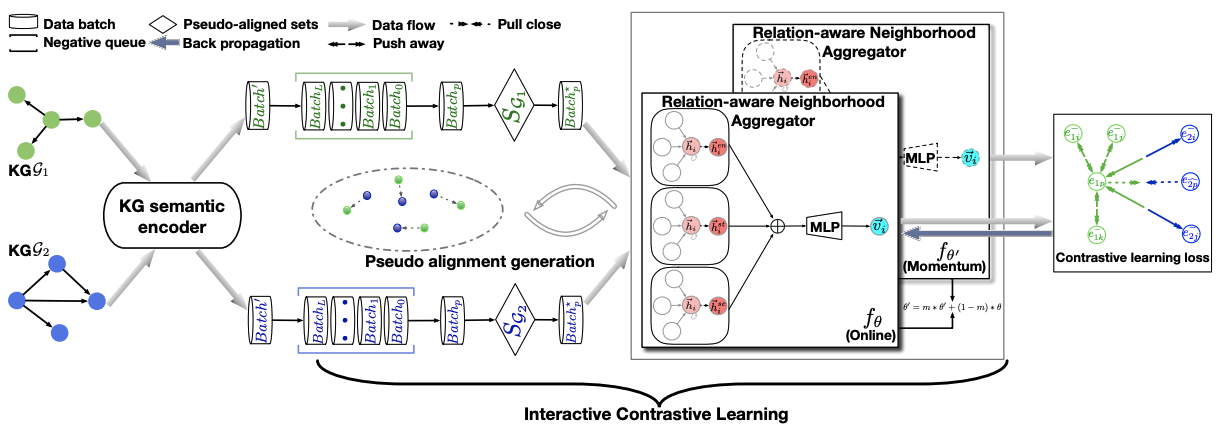 | ICLEA: Interactive Contrastive Learning for Self-supervised Entity Alignment CIKM 2022 Kaisheng Zeng, Zhenhao Dong, Lei Hou, Yixin Cao, Minghao Hu, Jifan Yu, Xin Lv, Juanzi Li, Ling Feng [PDF] In this paper, we propose an interactive contrastive learning model for self-supervised EA. The model encodes not only structures and semantics of entities (including entity name, entity description, and entity neighborhood), but also conducts cross-KG contrastive learning by building pseudo-aligned entity pairs. |
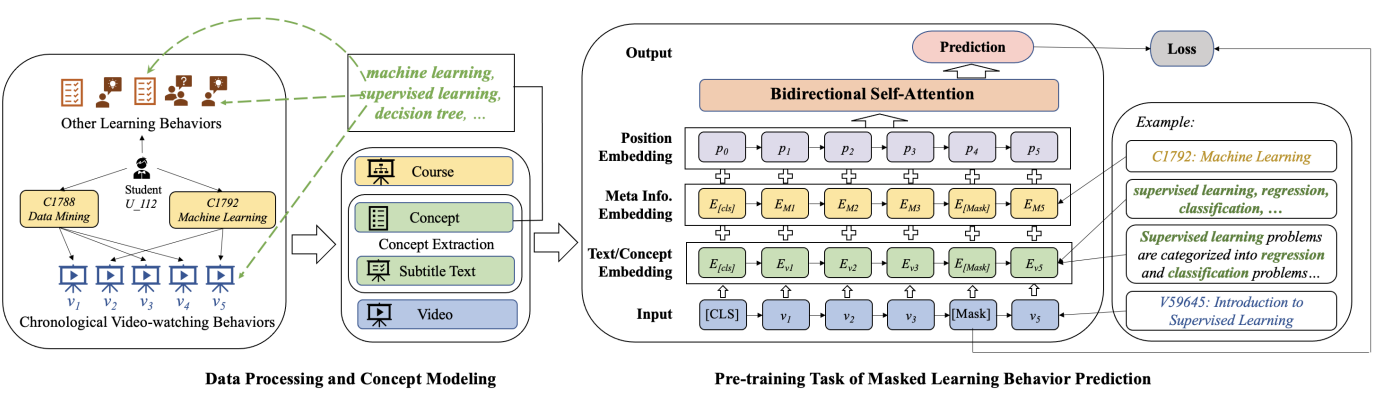 | Towards a General Pre-training Framework for Adaptive Learning in MOOCs Arxiv Qingyang Zhong*, Jifan Yu*, Zheyuan Zhang, Yiming Mao, Yuquan Wang, Yankai Lin, Lei Hou, Juanzi Li, Jie Tang [PDF] To realize the idea of general adaptive systems proposed in pedagogical theory, with the emerging pre-training techniques in NLP, we try to conduct a practical exploration on applying pre-training to adaptive learning, to propose a unified framework based on data observation and learning style analysis, properly leveraging heterogeneous learning elements. |
2021
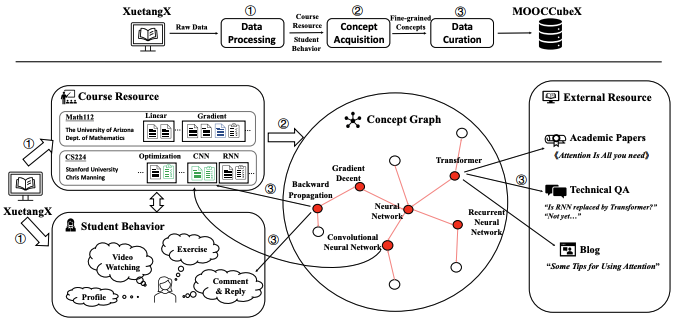 | MOOCCubeX: A Large Knowledge-centered Repository for Adaptive Learning in MOOCs (Best Resource Paper Nomination) CIKM 2021 Jifan Yu, Yuquan Wang, Qingyang Zhong, Gan Luo, Yiming Mao, Kai Sun, Wenzheng Feng, Wei Xu, Shulin Cao, Kaisheng Zeng, Zijun Yao, Lei Hou, Yankai Lin, Peng Li, Jie Zhou, Bin Xu, Juanzi Li, Jie Tang, Maosong Sun [PDF] [Code] We present MOOCCubeX, a large, knowledge-centered repository consisting of 4,216 courses, 230,263 videos, 358,265 exercises, 637,572 fine-grained concepts and over 296 million behavioral data of 3,330,294 students, for supporting the research topics on adaptive learning in MOOCs. |
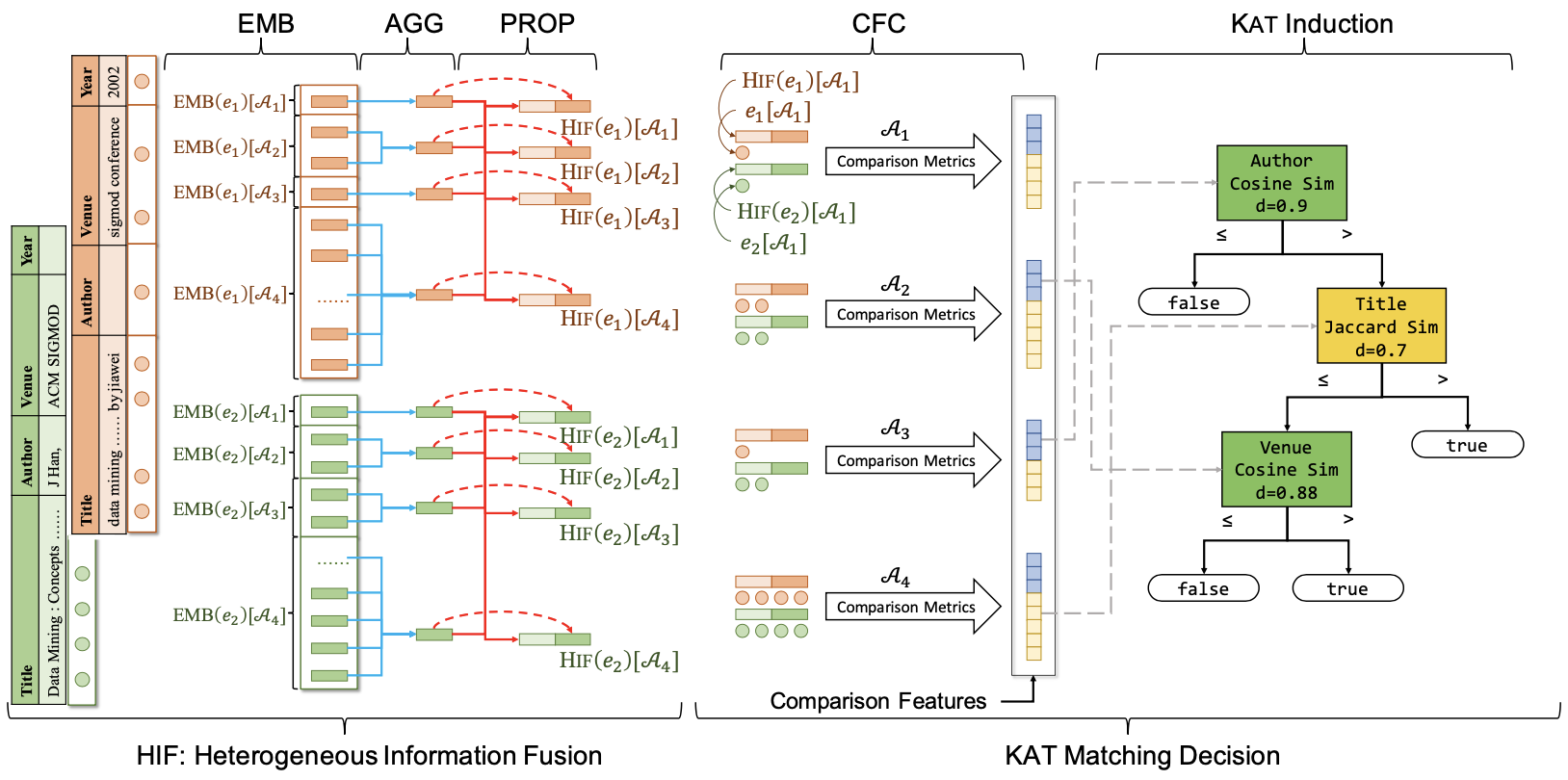 | Interpretable and Low-Resource Entity Matching via Decoupling Feature Learning from Decision Making ACL 2021 Zijun Yao, Chengjiang Li, Tiansi Dong, Xin Lv, Jifan Yu, Lei Hou, Juanzi Li, Yichi Zhang and Zelin Dai [PDF] [Code] [Slide] We propose to decouple the representation learning stage and the decision making stage to fully utilize unlabeled data for entity matching task. |
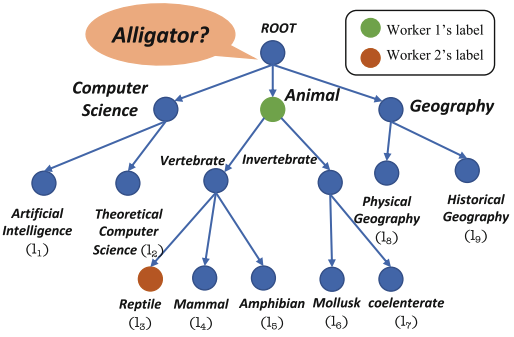 | Expertise-Aware Crowdsourcing Taxonomy Enrichment WISE 2021 Yuquan Wang, Yanpeng Wang, Yiming Mao, Jifan Yu, Kaisheng Zeng, Lei Hou, Juanzi Li, Jie Tang [PDF] [Code] In this work, we propose a unified crowdsourcing framework to mitigate both challenges. It leverages the skill locality of workers with a Graph Gaussian Process model. |
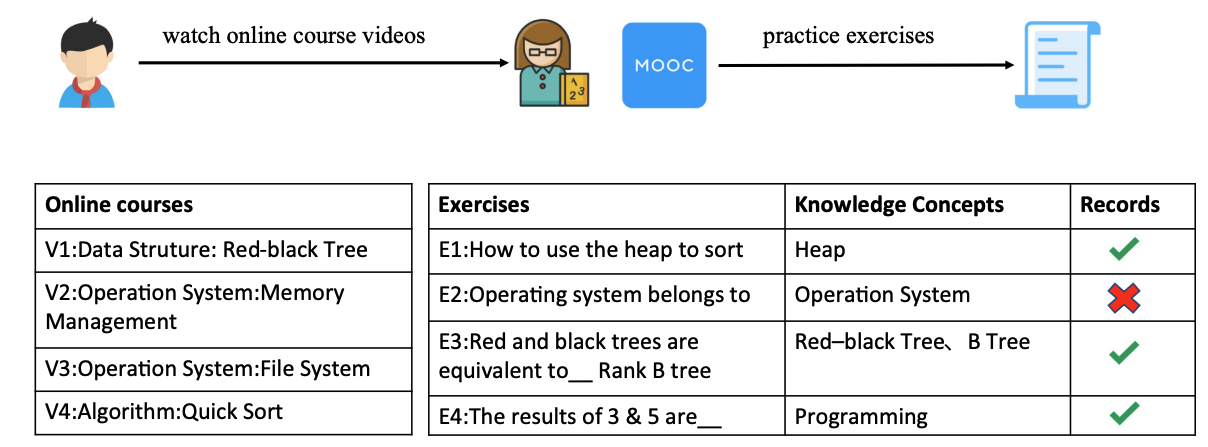 | Learning Behavior-Aware Cognitive Diagnosis for Online Education Systems ICPCSEE 2021 Yiming Mao, Bin Xu, Jifan Yu, Yifan Fang, Jie Yuan, Juanzi Li, Lei Hou In this paper, a learning behavior-aware cognitive diagnosis (LCD) framework is proposed for students’ cognitive modeling with both learning behavior records and exercising records. |
2020
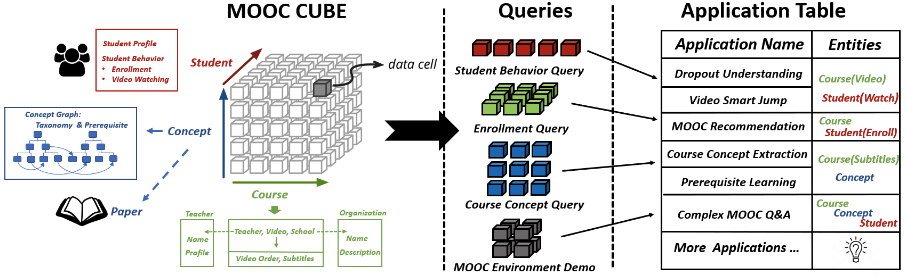 | MOOCCube: A Large-scale Data Repository for NLP Applications in MOOCs ACL 2020 Jifan Yu, Gan Luo, Tong Xiao, Qingyang Zhong, Yuquan Wang, Wenzheng Feng, Junyi Luo, Chenyu Wang, Lei Hou, Juanzi Li, Zhiyuan Liu, Jie Tang [PDF] [Code] We present MOOCCube, a large-scale data repository of over 700 MOOC courses, 100k concepts, 8 million student behaviors with an external resource. Moreover, we conduct a prerequisite discovery task as an example application to show the potential of MOOCCube in facilitating relevant research. |
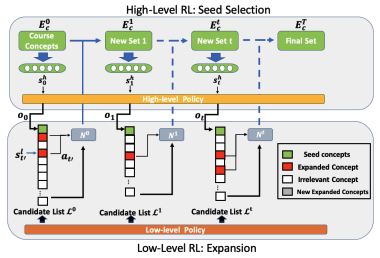 | Expanrl: Hierarchical Reinforcement Learning for Course Concept Expansion in MOOCs AACL 2020 Jifan Yu, Chenyu Wang, Gan Luo, Lei Hou, Juanzi Li, Jie Tang, Minlie Huang, Zhiyuan Liu [PDF] We present ExpanRL, an end-to-end hierarchical reinforcement learning (HRL) model for concept expansion in MOOCs. Employing a two-level HRL mechanism of seed selection and concept expansion, ExpanRL is more feasible to adjust the expansion strategy to find new concepts based on the students’ feedback on expansion results. |
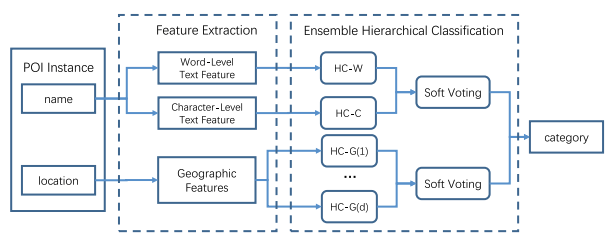 | Geographical Information Enhanced POI Hierarchical Classification AP-Web 2020 Shaopeng Liu, Jifan Yu, Juanzi Li, Lei Hou [PDF] We propose an Ensemble POI Hierarchical Classification framework (EHC) consisting of three components: Textual and Geographic Feature Extraction, Hierarchical Classifier, and Soft Voting Ensemble Model. |
2019
 | Course Concept Expansion in MOOCs with External Knowledge and Interactive Game ACL 2019 Jifan Yu, Chenyu Wang, Gan Luo, Lei Hou, Juanzi Li, Jie Tang, Zhiyuan Liu [PDF] In this paper, we first build a novel boundary during searching for new concepts via external knowledge base and then utilize heterogeneous features to verify the high-quality results. In addition, to involve human efforts in our model, we design an interactive optimization mechanism based on a game. |
2018
 | Predicting Concept-based Research Trends with Rhetorical Framing CCKS 2018 Jifan Yu, Liangming Pan, Juanzi Li, Xiaoping Du [PDF] The existing researches mainly use topics extracted from literatures as objects to build predicting model. To get more accurate results, we use concepts instead of topics constructing a model to predict their rise and fall trends, considering the rhetorical characteristics of them. |